
How to Reduce Crawl Waste So Important Pages Get More SEO Value using Crawl Efficiency Framework
As part of our SEO Agency in India hub, this Crawl Efficiency Framework helps large websites reduce crawl waste and improve the visibility of important SEO pages. Use it to identify low-value URL patterns, control faceted-navigation bloat, strengthen crawl paths to money pages and improve how search engines discover, crawl and prioritize high-value content.

TL;DR: Crawl Waste in One Box
Crawl waste happens when search engines spend crawl activity on URLs that do not deserve SEO attention: filter combinations, sort URLs, tracking parameters, duplicate variants, internal search pages, soft 404s, redirect chains, expired pages and thin archive pages.
The goal is not just to block weak URLs. The goal is to shift crawl attention toward pages that can generate rankings, leads, revenue and long-term organic visibility.
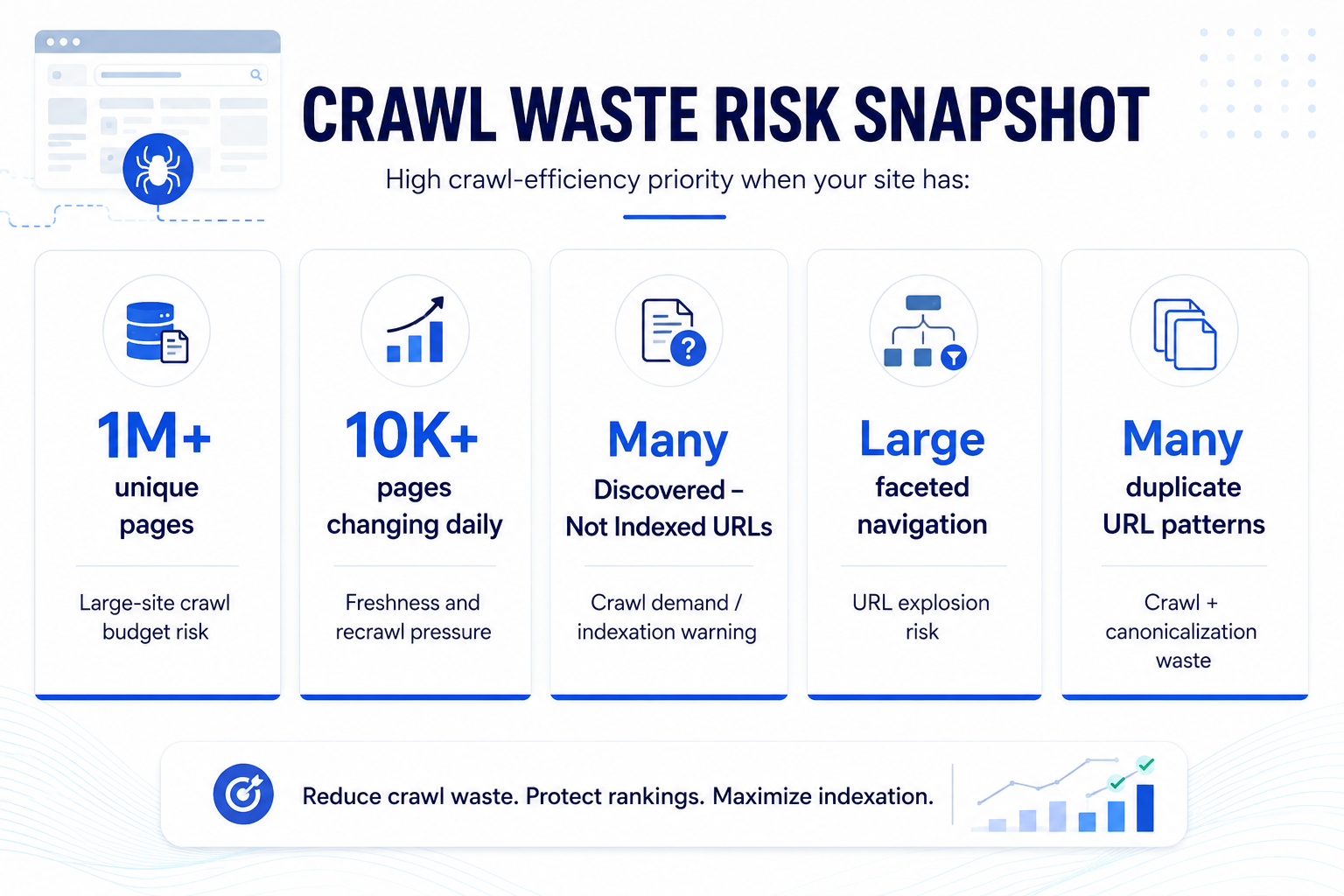
Unique pages
Google says crawl budget guidance is mainly relevant for very large sites, including sites around 1 million unique pages.
Daily-changing pages
Sites with 10,000+ pages that change daily are more likely to need crawl budget management.
Discovered not indexed URLs
Large counts of discovered but not indexed URLs are a warning sign that crawl demand and URL quality need review.
URL explosion risk
Parameter-based faceted navigation can create near-infinite URL spaces and slow discovery of useful pages.
Executive Summary
For small websites, crawl waste is rarely a major technical SEO constraint. For large sites, ecommerce stores, marketplaces and faceted navigation websites, it can become a serious discovery and indexation problem.
Google’s crawl budget guidance explains that crawl budget depends on crawl capacity and crawl demand. Capacity is influenced by server health and how efficiently Googlebot can fetch URLs. Demand is influenced by how useful, fresh, linked and important URLs appear to be.
Crawl efficiency work is therefore not only about robots.txt or noindex decisions. It is about mapping low-value URL patterns, controlling duplicate or infinite URL paths, and protecting valuable pages so search engines can discover, crawl, index and evaluate them more consistently.
Reduce waste
Limit crawl activity on URLs that have no indexation, ranking or business value.
Protect money pages
Make important pages indexable, canonical, internally linked, sitemapped and easy to reach.
Validate impact
Use crawl stats, indexing data, logs and performance data to confirm crawler attention shifted toward useful URLs.
Key Statistics and Evidence
Crawl efficiency becomes commercially useful when the audit connects crawl data to indexation, important page coverage and organic outcomes.
| Data Point | Source | Why It Matters | Caveat |
|---|---|---|---|
| Crawl budget guidance is mainly for sites with about 1M+ unique pages, 10K+ daily-changing pages or many URLs in “Discovered - currently not indexed.” | Defines when crawl efficiency becomes a serious SEO concern. | Google says these are rough estimates, not exact thresholds. | |
| Google says crawl budget depends on crawl capacity and crawl demand. | Crawl efficiency depends on server health and URL value. | Most relevant for large sites. | |
| Duplicate, removed or unimportant URLs can waste Google crawling time. | Confirms crawl waste is a real crawl demand issue. | Does not mean every small site needs crawl budget work. | |
| Faceted navigation can create infinite URL spaces. | Strong reason ecommerce sites need crawl controls. | Depends on implementation. | |
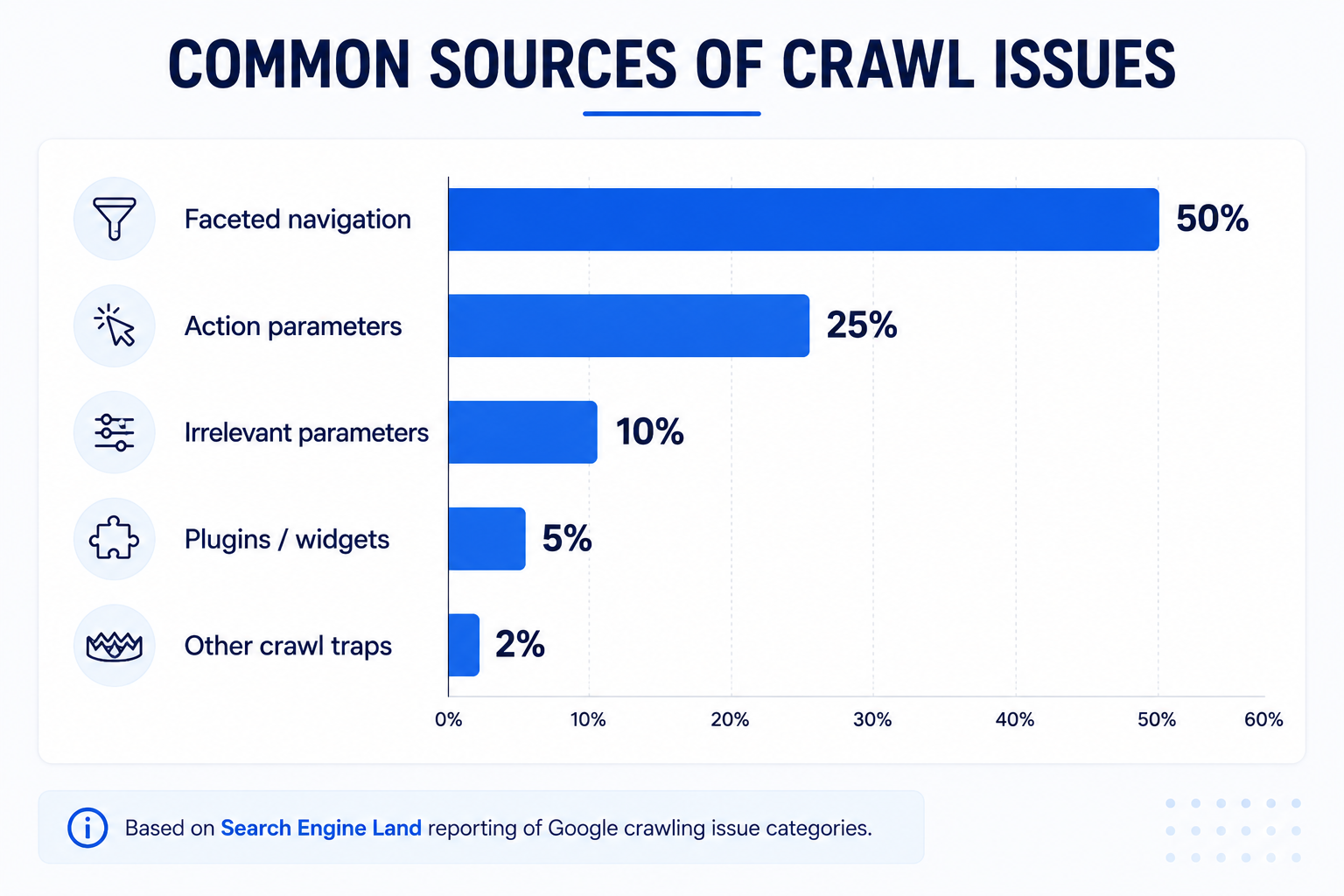
| Google’s Gary Illyes reportedly said 75% of crawling issues came from faceted navigation and action parameters; facets accounted for about 50%. | Search Engine Land | Shows faceted navigation is a major crawl issue category. | Reported from Google podcast coverage. |
| One ecommerce site with fewer than 200,000 products had over 500 million accessible pages because of faceted navigation. | Botify | Shows how facets can multiply URL inventory. | Vendor example, not universal benchmark. |
| 1001Pneus achieved 80% less crawl budget waste after log-based crawl optimization. | Oncrawl | Shows crawl waste reduction can be measurable. | Single case study. |
| Blibli reported +39% pages crawled, +50% pages indexed and +30% organic transactions after crawl/indexation optimization. | Botify | Connects crawl optimization to business impact. | Single case study. |
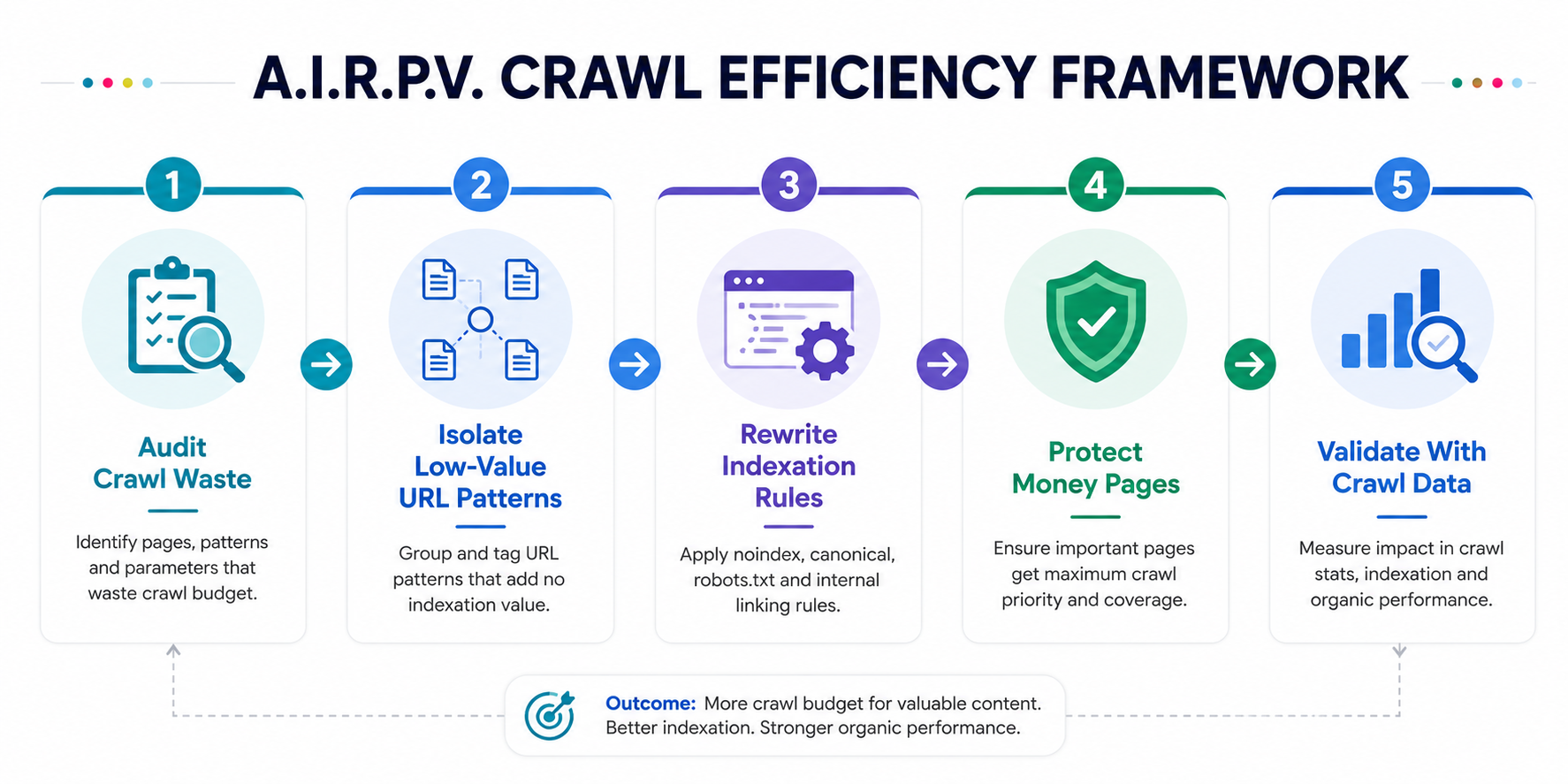
The A.I.R.P.V. Crawl Efficiency Framework
The A.I.R.P.V. model turns crawl budget optimization from a vague technical SEO task into a measurable workflow. Each step has one job: find waste, group it, apply the right crawl/index rules, protect important pages and prove the impact with crawl data.
Audit Crawl Waste
Find what Googlebot is crawling that has low SEO value.
Isolate URL Patterns
Group paths, parameters, templates and page types that create waste.
Rewrite Indexation Rules
Decide whether to index, noindex, canonicalize, redirect, block or remove.
Protect Money Pages
Ensure revenue-driving pages get crawl priority and indexation support.
Validate With Data
Measure the shift from crawl waste to valuable URL discovery.
| Step | Goal | Main Question | Key Output |
|---|---|---|---|
| A - Audit Crawl Waste | Find where crawl activity is going. | What is Googlebot crawling that has low SEO value? | Crawl waste audit. |
| I - Isolate Low-Value URL Patterns | Group waste by URL pattern. | Which paths, parameters, templates or page types create waste? | URL pattern library. |
| R - Rewrite Indexation Rules | Decide crawl and index rules. | Should this pattern be indexed, noindexed, canonicalized, redirected, blocked or removed? | Crawl control rule map. |
| P - Protect Money Pages | Strengthen important pages. | Are revenue-driving pages easy to crawl, index and understand? | Money page protection checklist. |
| V - Validate With Crawl Data | Prove improvement. | Did crawl activity shift from low-value URLs to important pages? | Before/after crawl report. |
Step 1: Audit Crawl Waste
Use multiple data sources, not just a crawler. A crawler tells you what can be found from internal links. Server logs and Search Console show what Google is actually requesting, excluding, indexing or ignoring.
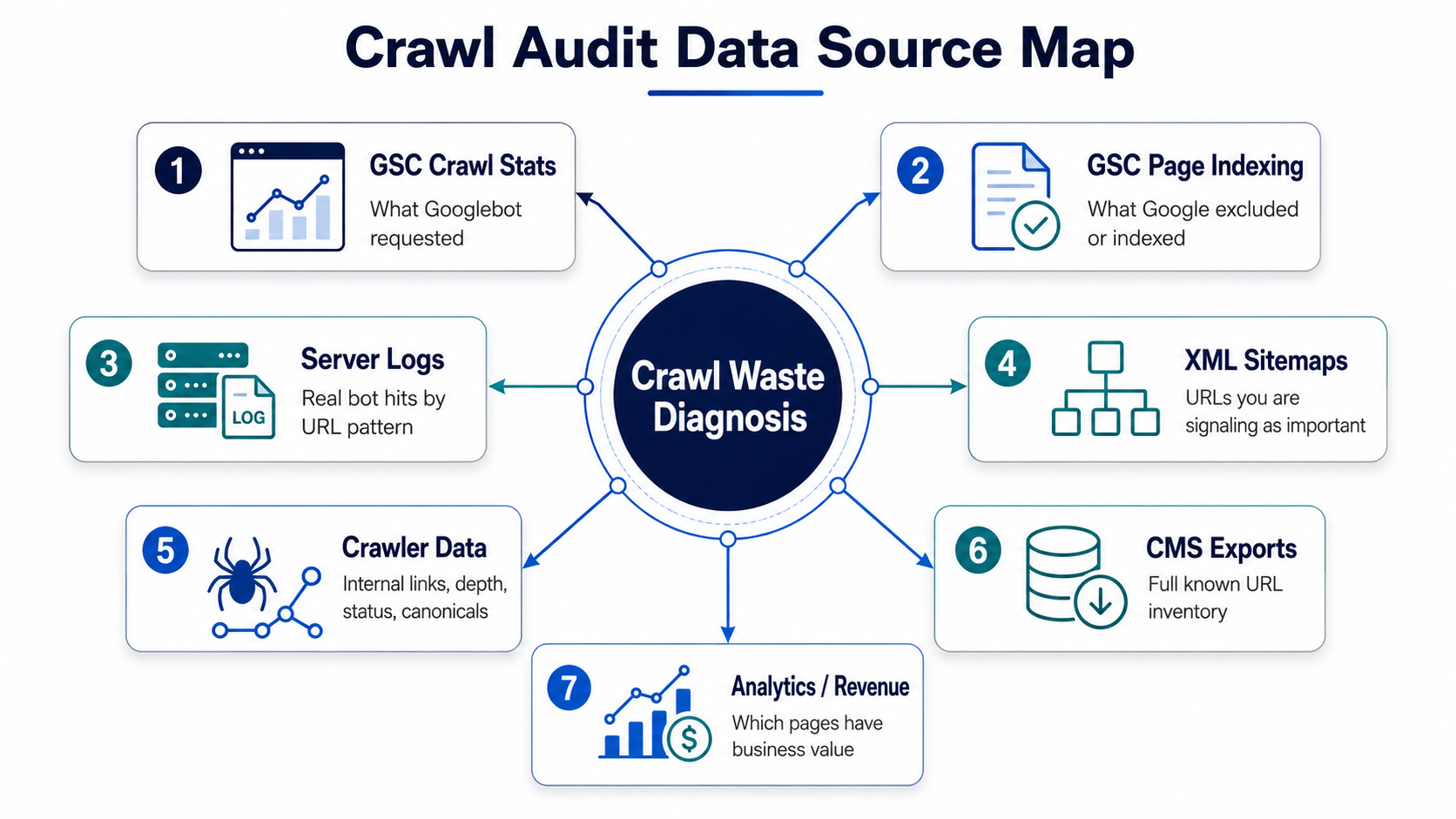
| Data Source | What It Reveals |
|---|---|
| GSC Crawl Stats | Crawl requests, response codes, file types, crawl purpose and average response time. |
| GSC Page Indexing | Discovered not indexed, crawled not indexed, duplicate, soft 404 and alternate canonical issues. |
| Server logs | Real Googlebot hits by URL, status code, timestamp and frequency. |
| XML sitemaps | Which URLs you are signaling as important. |
| Screaming Frog / Sitebulb | Internal links, crawl depth, status codes, canonicals, noindex and duplicates. |
| CMS / product exports | Full known URL inventory. |
| Analytics / GSC performance | Which URLs drive traffic, impressions, leads, sales or assisted value. |
Step 2: Isolate Low-Value URL Patterns
Do not fix crawl waste URL by URL. Fix it by pattern. Pattern-level controls are more scalable, safer and easier to validate across a large site.
| Pattern Type | Example | Risk |
|---|---|---|
| Sort URLs | /shoes?sort=price-low | Duplicate content and crawl waste. |
| Filter URLs | /shoes?color=black&size=10 | Faceted crawl traps. |
| Tracking URLs | /page?utm_source=email | Duplicate URL inventory. |
| Session URLs | /product?sid=123 | Infinite duplicate URLs. |
| Internal search | /search?q=running+shoes | Thin or duplicate indexed pages. |
| Product variants | /shirt?size=m | Duplicate product clusters. |
| Tag archives | /tag/random-topic/ | Index bloat. |
| Redirect chains | /old-a to /old-b to /new-c | Fetch waste. |
| Soft 404s | Empty page returning 200 | Crawl and indexation waste. |
Step 3: Improve Indexation Rules
The right control depends on what you need the URL to do. A noindex tag, a canonical tag, robots.txt, a 301 redirect and a 404/410 response are not interchangeable.
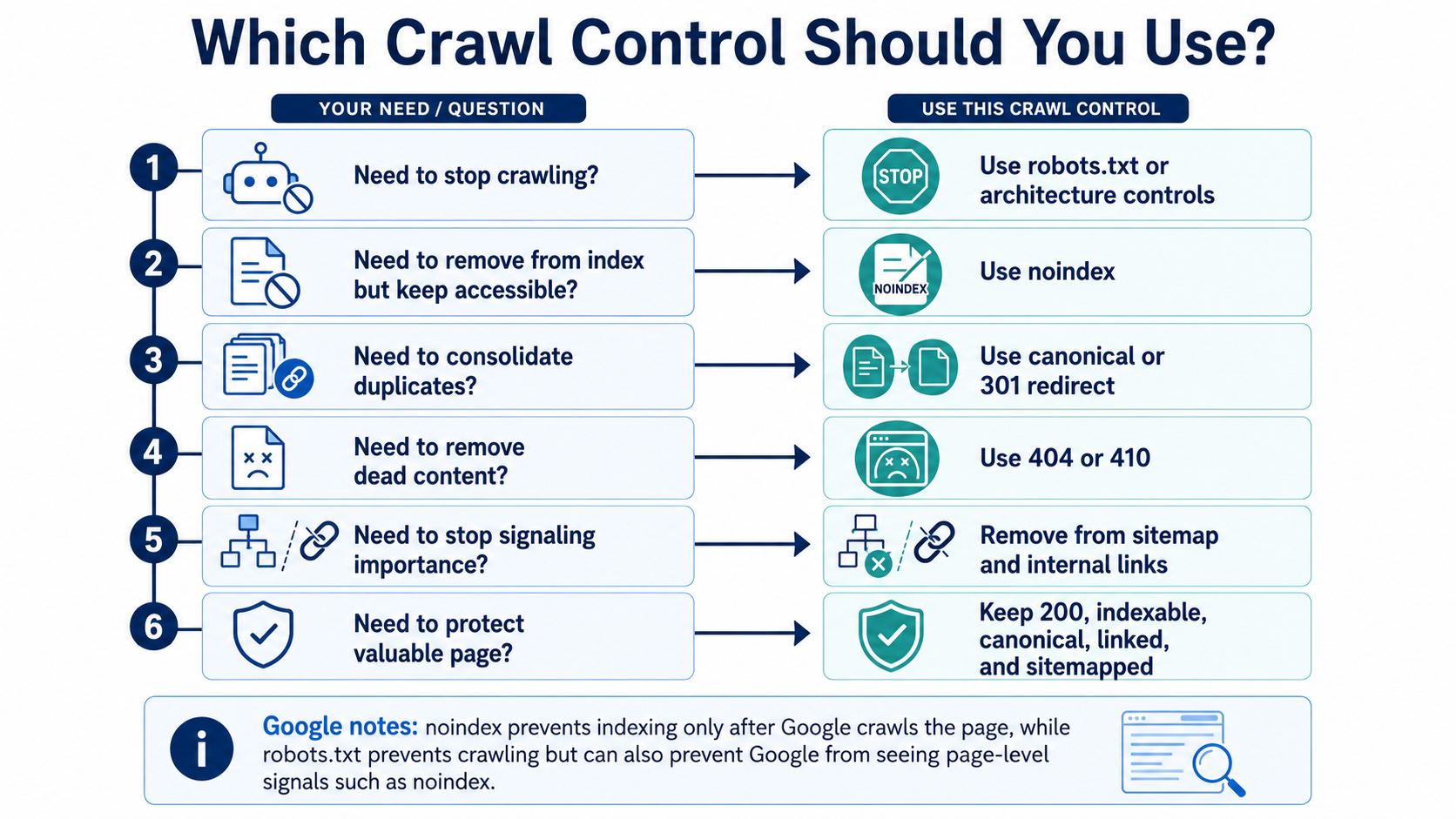
| URL Type | Best Rule | Why |
|---|---|---|
| True duplicate URL | 301 redirect or canonical | Consolidates signals. |
| Similar product variant | Canonical or dedicated variant strategy | Avoids duplicate clusters. |
| Low-value filtered page | Noindex or block crawl depending on use case | Keeps weak pages out of index. |
| Sort URL | Usually noindex or disallow | Sorting rarely creates unique search value. |
| Internal search page | Usually noindex or disallow | Often thin and infinite. |
| Expired page with replacement | 301 redirect | Preserves relevance and authority. |
| Permanently removed page | 404 or 410 | Sends a removal signal. |
| Tracking parameter | Canonical to clean URL | Prevents duplicate indexing. |
| Valuable filtered page | Indexable, self-canonical, internally linked | Converts useful facet into an SEO landing page. |
Noindex controls indexing
Google must crawl the page to see the noindex directive, so noindex is not the same as crawl prevention.
Robots.txt controls crawling
If a URL is blocked, Google may not see page-level signals such as noindex or canonical tags.
Canonical is a hint
Google considers redirects, rel=canonical, sitemap inclusion, internal links and other signals when choosing canonicals.
Step 4: Protect Money Pages
Money pages are URLs that directly support revenue, leads or strategic visibility. These include product pages, category pages, collection pages, service pages, location pages, comparison pages, programmatic SEO pages and high-value guides.
| Check | Target | Why It Matters |
|---|---|---|
| Status code | 200 | Important pages should not waste crawl hops through redirects or errors. |
| Indexability | Indexable | A money page cannot rank if it is blocked or noindexed by mistake. |
| Canonical | Self-canonical or intentional canonical | Avoids duplicate consolidation mistakes. |
| Sitemap | Included if canonical and indexable | Reinforces discovery and importance signals. |
| Internal links | Linked from relevant hubs/categories | Improves discoverability and authority flow. |
| Crawl depth | Ideally within 3 clicks from key hubs | Important pages should not be buried. |
| Redirects | No redirect hops | Reduces fetch waste and preserves direct signals. |
| Logs | Confirm Googlebot is crawling it | Validates that the page is actually receiving crawl attention. |
Money Page Protection Scorecard Checker
Use the checklist below as a quick diagnostic for any important page. A low score means the page may be under-protected from a crawl, indexation, internal linking or canonicalization perspective.
Money Page Protection Scorecard Checker
Technical SEO scorecard for protecting and strengthening your most valuable pages.
Recommended fixes
- Select the criteria this page already meets to generate a prioritized fix list.
This is a heuristic scorecard. Validate every issue with your own crawl reports, Search Console data, log files and on-page audits before acting.
Step 5: Validate With Crawl Data
Crawl efficiency work should end with a before/after report. The goal is to prove that crawler activity moved away from low-value patterns and toward important URLs.
| Metric | Desired Direction |
|---|---|
| Crawl hits to low-value URLs | Down |
| Crawl hits to money pages | Up |
| Indexed money pages | Up |
| Valuable URLs in Discovered - currently not indexed | Down |
| Valuable URLs in Crawled - currently not indexed | Down |
| Soft 404s | Down |
| Redirect chain requests | Down |
| Average response time | Down |
| Sitemap submitted vs indexed ratio | Up |
| Organic impressions from money pages | Up |
| Organic clicks and conversions | Up |
Google recommends eliminating soft 404s, keeping sitemaps updated, avoiding long redirect chains, improving load efficiency and monitoring crawling for large sites.
Crawl Waste Score
Use this as a proprietary diagnostic score for comparing crawl efficiency before and after technical SEO fixes. It is not an official Google metric.
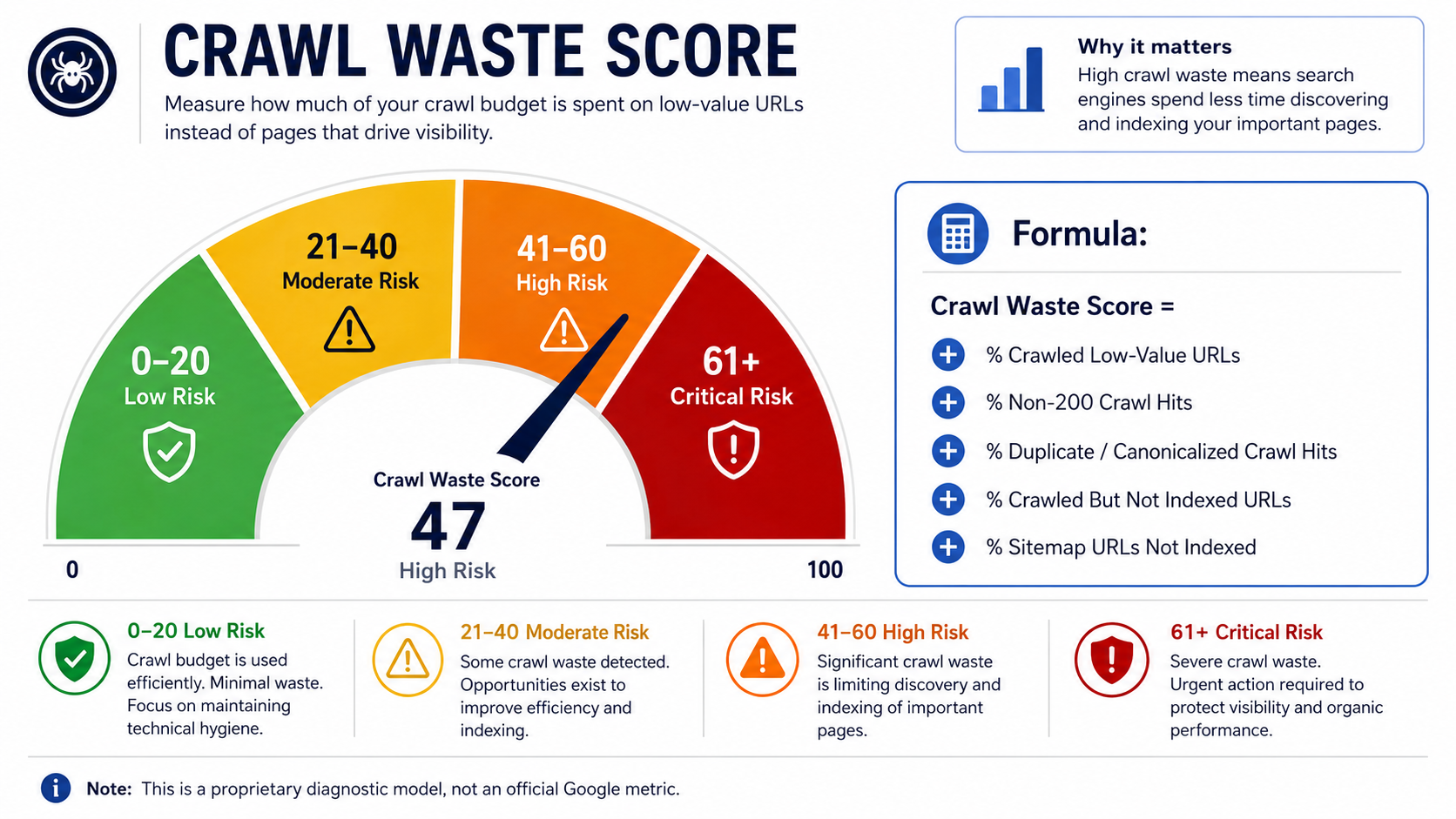
Crawl Waste Score Formula
Crawl Waste Score = the combined percentage impact of the following crawl-waste signals.
URL Pattern Decision Matrix
Use this matrix to decide whether each URL pattern should be crawled, indexed, included in sitemaps and supported with internal links.
| URL Pattern | Crawl? | Index? | Sitemap? | Best Rule |
|---|---|---|---|---|
| Main category | Yes | Yes | Yes | 200 + self-canonical |
| Subcategory | Yes | Yes | Yes | 200 + self-canonical |
| Valuable filtered page | Yes | Yes | Yes | Dedicated landing page |
| Low-value filter | Usually no | No | No | Noindex / disallow / control links |
| Sort URL | Usually no | No | No | Disallow or noindex |
| Internal search | Usually no | No | No | Disallow or noindex |
| Product variant | Situational | Situational | Usually no | Canonical or variant strategy |
| Out-of-stock product | Situational | Situational | Situational | Keep, redirect or remove |
| Discontinued product | Usually no | No | No | 301 or 410 |
| UTM URL | No | No | No | Canonical clean URL |
| Session URL | No | No | No | Prevent generation |
| Soft 404 | No | No | No | Real 404 or improved page |
| Redirected URL | One fetch only | No | No | Single-hop 301 |
Common Mistakes
| Mistake | Correct Approach |
|---|---|
| Treating noindex as a crawl budget fix | Use noindex for index control, not crawl prevention. |
| Blocking URLs before Google sees canonicals | Use robots.txt only when the URL should not be crawled at all. |
| Adding non-indexable URLs to sitemaps | Include only canonical, indexable, 200 URLs. |
| Letting every facet generate an indexable URL | Index only demand-backed facets. |
| Removing out-of-stock products too fast | Keep if temporary, valuable or likely to return. |
| Ignoring soft 404s | Return real 404/410 or improve the page. |
| Allowing redirect chains | Collapse to one-hop redirects. |
| Linking internally to blocked URLs | Link to canonical, indexable URLs. |
| Not checking logs | Validate with actual Googlebot behavior. |
Download the Crawl Waste Scorecard
Use the scorecard to classify URL patterns, calculate crawl waste and identify which important SEO pages need better crawl protection.

Want to reduce crawl waste before it damages important SEO pages?
Supramind Digital helps large sites, ecommerce brands and marketplace teams audit crawl waste, protect money pages and improve crawl-to-index performance with a structured technical SEO framework.
Final Framework Summary
The Crawl Efficiency Framework helps large websites reduce SEO waste by making crawler activity more intentional. The winning formula is simple: less crawler attention on low-value URLs and more crawler attention on important, indexable, revenue-driving pages.
Use the A.I.R.P.V. model to audit crawl waste, isolate low-value URL patterns, rewrite indexation and crawl rules, protect money pages and validate results with crawl and indexation data. This turns crawl budget optimization into a measurable, repeatable SEO process.
FAQ
What is crawl waste?
Crawl waste happens when search engines spend crawl activity on URLs with little or no SEO value, such as duplicate filters, sort pages, tracking URLs, soft 404s, redirect chains, internal search pages or thin archives.
Is crawl budget optimization important for every website?
No. Crawl budget management is usually most relevant for very large sites, sites with many frequently changing URLs, or websites with major indexation bloat. Smaller sites usually benefit more from content quality, internal links and technical hygiene.
Should I use noindex or robots.txt for low-value pages?
Use noindex when Google can crawl the page but should not index it. Use robots.txt when the URL should not be crawled at all. Do not block a URL before Google can see page-level noindex or canonical signals unless crawl prevention is truly the goal.
Which pages should get crawl priority?
Money pages should get priority. These include product pages, category pages, collection pages, service pages, location pages, comparison pages, programmatic SEO pages and high-value guides that support revenue or strategic visibility.
How do I measure crawl efficiency improvements?
Track crawl hits to low-value URLs, crawl hits to money pages, indexed money pages, discovered/crawled-not-indexed URLs, soft 404s, redirect chain requests, average response time, sitemap indexation ratio, organic impressions, clicks and conversions.
Sources
- Google: Crawl budget guidance
- Google: Faceted navigation best practices
- Search Engine Land: Google’s biggest crawling issues
- Botify: Faceted navigation SEO
- Oncrawl: 1001Pneus Googlebot crawling case study
- Botify: Blibli crawl and indexation case study
- Botify: Crawl budget optimization for classified websites
- Log in to post comments

 INDIA
INDIA